Nuestro trabajo se centra en un dataset con información relacionada a trabajos de Estados Unidos. La idea del dataSet es poder predecir el salario de los trabajos utilizando modelos que nos permitan predecir información.
Los datos fueron encontrados en Kaggle. El cual es un dataset de libre uso para el análisis de datos, en el siguiente link https://www.kaggle.com/andrewmvd/data-analyst-jobs/tasks. El cual cuenta con 2253 filas y 16 columnas. Las propiedades del dataset se definen de la siguiente manera.
1. Id: esta propiedad es solamente un número que identifica cada una de las filas del dataset
2. Job Title: este describe el titulo o nombre del empleo
3. Salary Estimate: esta propiedad tiene un rango de cuanto paga cada uno de los trabajos. Esta información fue encontrada en Glassdoor.
4. Job Description: tiene información relaciona a que es el trabajo que se va a desempeñar.
5. Rating: evaluación que le dan los empleados a las empresas
6. Company name: el nombre la compañía que se está evaluando
7. Location: donde se encuentra ubicada la empresa
8. Company Headquartes location: la ubicación de la compañía
9. Size: la cantidad de empleados con los que cuanta la compañía.
10. Founded: el año cuando fue fundada la compañía
11. Type of ownership: el tipo de compañía que se va a analizar
12. Industry: la industria a la que pertenece la empresa
13. Sector: el sector en el que esta la industria de la empresa
14. Revenue: cuanto genera la compañía
15. Competitors: cuales con los posibles competidores de la empresa
16. Easy Apply: Si es fácil aplicar para la empresa o no
Lo primero que se realizó fue cargar el documento en Python para ver su contenido. Se hace un head para ver el contenido rápidamente del dataset. Luego se realiza un análisis de la estructura del dataset, esto para ver que tipos de objetos tiene cada una de las columnas. Después de esto se pasa verificar si existen valores nulos en el dataset.
Para poder hacer algunos análisis se requiere cambiar los valores alfanuméricos a valores numéricos, por lo que se carga otro dataset para poder analizar la información tanto en su estado original como en con sus valores numéricos ya que se van a tener que hacer algunas transformaciones de datos.
Durante el proceso se crean diferentes dataset para analizar diferentes cosas, por ejemplo, se crea un pequeño dataset con el salario, título del trabajo y raiting del empleo. Esto para verificar algunas preguntas que teníamos del set de datos.
Utilizando ordenamiento se busca información relacionada a los mejores salarios comparándolos con las calificaciones de las personas. Con esto podemos encontrar datos interesantes del dataset y determinar que únicamente con estos criterios no podemos predecir correctamente los salarios. Definitivamente se va a requerir más datos.

Se inicia hacer algunos gráficos para ver los datos. Por ejemplo, la relación que existe entre Salary Estimate y Job Title. Los gráficos inicialmente son un poco difíciles de interpretar ya que tiene muchos datos por lo que se va a crear datasets más pequeños. La idea es poder entender mejor los datos utilizando set de datos que se pueden visualizar en los gráficos.
Se crear más ordenamientos para ir entendiendo los datos de manera simple. Lo primero que se hace es ordenar los datos por medio del rating para verificar si los salarios más altos se encurtan ubicados entre las empresas con mayores calificaciones o si no es así. Esto se logra utilizando la función sort_values de Python que además permite crear ordenamiento por diferentes tipos de valores del set de datos. Se hacen ordenamientos por medio del Salary Estimate para poder ver si las empresas con los salarios más altos cuentan con las mejores calificaciones con esto se puede determinar que las mejores calificaciones no están estrictamente relacionas a los mejores salarios de las personas. Por lo que se debe realizar otra serie de estudios para encontrar mayores relaciones entre los datos con los que contamos.
La idea de hacer conjuntos de datos más pequeños realmente nos ayudo a crear muchas observaciones que se pueden graficar y estudiar de manera detallada. Parte de las observaciones que se hacen están basadas en los supuestos con los que se inicial el proyecto para predicción de salarios.
Se hacen otros filtros de datos con diferentes valores para ir inspeccionando la información un poco más y de esta manera comprendiendo mucho mejor con que estamos tratando.
Continuando con el proceso de análisis de datos iniciamos a ver la información que contenía cada una de las propiedades de nuestro dataset. Utilizando la función unique de Python buscamos los valores únicos de las diferentes columnas con el fin de poder generar valores únicos para cada una de las variables. Ya que algunos procedimientos y modelos no soportan datos alfanuméricos.
Nos damos cuenta de que los valores de las columnas en algunos casos son muchísimos por lo que transformar esto de manera manual no es simple. Con esto se decide a crear un algoritmo que nos permite transformar los datos de manera automática, pero tenemos que guardar la equivalencia de cada uno de estos datos para futuros estudios.
El algoritmo que creamos realmente es muy simple. Lo que hacemos es buscar el valor único de cada una de las columnas que tenemos en el dataset. Creamos una lista que se encarga de asignar un valor numérico para cada uno de los valores de texto que tiene cada columna. Al final como resultado tenemos una lista que cuenta con un formato llave/valor para representar el valor numérico equivalente al dato que tenia el set de manera original.
El proceso fue encontrar los valores únicos de cada una de las columnas con esto se generaron valores numéricos que representaran cada de los datos. Cada columna del dataset tiene una lista que contiene sus valores números para futuros procesos, esto con el fin de no olvidar que representa cada uno de los nuevos datos del conjunto. Luego de esto se crea un ciclo que se encarga de recorrer la columna e ir cambiando el valor alfanumérico por el valor numérico que representa el dato que tenemos en nuestro dataset.
Este último proceso se corrió para cada una de las columnas que no tenían valores numéricos.
En el caso de la columna Easy Apply esto es un valor true/false lo que representa valores de verdadero o falso. Esta columna no tenia todos los datos completos y con algunos -1 dentro de su información. Todos los valores de true se convirtieron en 1 los otros fueron convertidos a 0. Este fue un poco más simple ya que no teníamos esa cantidad enorme de datos como las otras columnas.
La ultima columnas a la que nos tocaba analizar para ver que podíamos hacer con esta era la columna de job description. Tomamos el tiempo de ver qué tipo de información teníamos en esta columna. Se encuentran los valores únicos de esta columna y prácticamente toda la información que tenia esta columna era de filas únicas. Es decir, cada una de las diferentes descripciones de los trabajos eran únicos. Lo que nos llevo a la tarea de analizar el contenido y fuimos viendo la información que tenía. Esta columna realmente no tenía información cuantificable o medible. Lo que nos daba esta columna eran datos de qué tipo de trabajo se estaba hablando, algunas descripciones de roles y tipos de personas que podrían estar interesadas en el trabajo. Por ejemplo, algunas hablaban de que querían personas que fueran muy trabajadoras, etc. Pero no le estaban aportando un valor real al estudio que se deseaba hacer.
Llegamos a la conclusión que lo mejor seria quitar la columna de nuestro estudio. Ya que no nos estaba dando un valor importante a nuestro análisis.
Para continuar con el proceso se hace una inspección de la estructura de los datos ya con la transformación. Nos damos cuenta de que algunos tipos de datos no son de tipo int. Esto da problemas con algunas tareas de análisis de datos.

Por lo que nos dimos a la tarea de convertir todos los tipos de datos a int32 que realmente era la forma en la que teníamos almacenados ahora la información. Esto nos permite trabajar con la información que tenemos con todos los modelos y procesos de visualización que queríamos crear.
El resultado de dataset por procesar fue con una estructura de tipos de datos numéricos (int32) que nos permitirá utilizar todos los tipos de gráficos y modelos.

Nos dimos cuenta de que teníamos pendiente una columna más por analizar la cual era founded. Esta columna representa cuando la empresa fue fundada, pero en algunos casos tenia un -1 que representa que no tiene una fecha de su fundación. Por lo que se realizo otra transformación de datos y pasamos este dato a un 0. Ahora el 0 representa que la compañía no tiene fecha de fundación.
A partir de este punto se inicia otra serie de análisis datos para ver cómo podemos entender mejor la información con la que contamos.

Como podemos observa en este grafico se hace un conteo de los tipos de salarios. Que tenemos en los datos. Esto nos demuestra cual es el salario más ofrecido por las diferentes empresas. Podemos visualizar de manera simple como se agrupan los rangos salariales que tenemos. Además de esto se continúa haciendo otros tipos de gráficos con diferente tipo de información para poder entenderla mucho mejor. Algunos gráficos son difíciles de entender ya que la cantidad de información es muy amplia.
Con este problema lo que hacemos es crear subdatasets con filtros que nos permitan ver información de manera más fácil. Por ejemplo, tomamos todos los datos de las empresas con mejores calificaciones y con este extracto de datos creamos gráficos.

Esta técnica sin ninguna duda permite entender mejor la información y crear datos que nos permitan responder a interrogantes específicas. Este proceso lo hicimos varias veces con el fin de entender diferentes partes de la información con la que estamos trabajando. El filtrar la información nos da mayor control sobre lo que deseamos investigar y los resultados que estamos buscando.
De esta forma por ejemplo se pudo encontrar la relación que tenemos de los mayores salarios y las evaluaciones de las personas.
Ahora es momento de trabajar con los modelos. Para hacer este trabajo se desarrollaron tres modelos diferentes para 3 tipos de datasets.
Los modelos fueron
· SVR
· RF
· LinearRegression
En el caso de los dataset fueron seleccionados de la siguiente forma. Uno que encontramos directamente en la página que proponía cuales eran los valores que se debían seleccionar para crear los modelos, este fue tomado como el modelo de criterio experto. En el caso de los otros dos modelos se generar proceso para hacer un feature selection usando librerías de Python. El primero dataset se utilizo el algoritmo de SelectKBest y luego el ExtraTreeClassifier. Estos dos últimos nos dieron columnas muy similares sin embargo si existían diferencias. Por lo que se toma la decisión de usar ambos para crear modelos y ver cual nos brinda mejores resultados.
El primer modelo que de criterio experto contiene los siguientes atributos
· Industry
· Location
· Compny revenue
El modelo que con el algoritmo kBest
· Job Title
· Salary Estimate
· Company Name
· Location
· Headquartes
· Founded
· Type of ownership
· Industry
· Sector
· Revenue
· Competitor
El modelo ExtreTreelassifier
· Job Title
· Salary Estimate
· Compnay name
· Location
· Headquarters
· Size
· Founded
· Type of ownersh
· Industry
· Sector
· Revenue
Ya con estos dataset se procede a crear una variable para cada dataset que contenga la variable dependiente que será la que vamos a predecir.
Después de esto se crean los dataset que vamos a usar, pero sin la variable dependiente esto con el fin de crear los sets de entrenamiento y de pruebas. Para cada uno de los dataset se crea una parte de pruebas y una parte de entrenamiento. Se analiza la información que contiene los sets de entrenamiento y pruebas solo para ver que fuero creados correctamente.
Luego debemos importar algunas librerías extras de Python para poder ejecutar algunos modelos que se requieren para poder predecir la información.
Para la creación de los modelos más simple se hacen variables que contiene cada uno de los modelos para cada uno de los datasets.

El siguiente paso que tenemos que hacer es iniciar a construir los modelos. Utilizando los datos de entrenamiento vamos a crear cada uno de los modelos.
En total vamos a generar 9 modelos que tenemos que analizar para ver cual nos da mejores resultados. Con esto vamos a generar estadísticas que nos permitan entender cual es el modelo que vamos a utilizar basados en las estadísticas que se fueron generando en el proyecto.
Detalle de las estadísticas
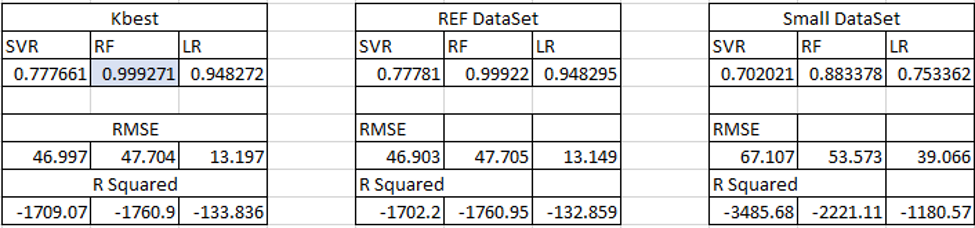
En el cuadro anterior podemos observar las estadísticas que hemos generado con los modelos para la predicción de los empleos.
Nos damos cuenta de que el dataset con la menor cantidad de datos no es el que nos genera los mejores resultados. Los dos dataset que usan la selección de atributos utilizando las funciones de Python nos dan mejores resultados a la hora de predecir la información.
Nos damos cuenta de que no siempre el uso del criterio experto nos da los mejores resultados es mejor crear estudios un poco más profundos para poder comprender mejor que atributos son los correctos para mejorar las predicciones.
Código de Python https://github.com/jeanPython/jobbSalary/blob/master/Job%20Salary.ipynb